What Is an Agent Harness?
The Loop that Makes a Model Useful
Not long ago, using an LLM was simple. You sent a prompt. You got a response. Then came web search, reasoning, and tool use. In the simplest form, the model was just a function: Request in, Response out.
That changed. And it changed fast.
Take your favorite coding agent - Cursor, Claude Code, Codex. You ask it to fix a bug. It starts grepping around your codebase, reads a few files, reasons about what it found, and changes direction when the first guess looks wrong. Only after it has built enough context does it make a change. Then it validates the fix, adjusts if needed, and eventually gives you a summary of what changed and what is still unresolved.
Agent harness sounds like one of those buzzwords that gets thrown around once a category starts forming. But the idea is simple: once an LLM stops being a one-shot chatbot and starts acting in a loop, something has to manage that loop.
That "something" is the harness.
The Loop
Every agent runs on some version of the same cycle:
- Plan/Reason - figure out what to do next given the current state
- Act - call a tool, run code, search something, write to disk
- Observe - look at what happened
- Repeat - adjust the plan and repeat
This is usually called the ReAct loop (Reason + Act). Initially, libraries like LangChain provided scaffolding to build these loops, and models often needed few-shot examples to reason and call tools. As models got better at reasoning and following instructions, the amount of scaffolding required dropped, and that is where agents started becoming mainstream.
A single prompt-response pair has one shot at being right. An agent running in a loop has many. It can catch its own mistakes. It can recover. It can try a different approach when the first one fails. With inference costs coming down, long-running loops became even more viable.
Anatomy of an Agent Harness
Harness is all the scaffolding and infrastructure around the model that makes it useful for complex, long-running tasks.
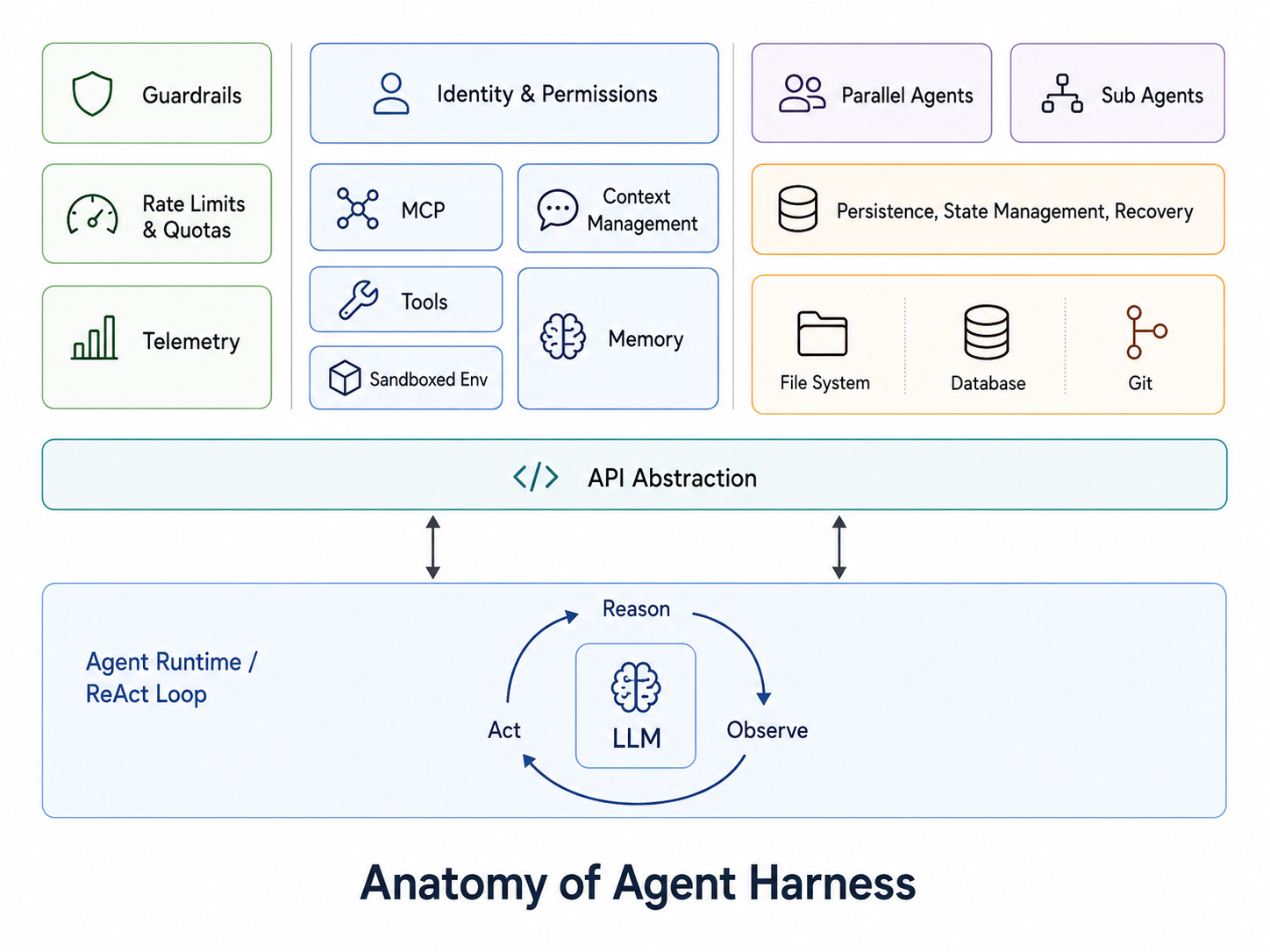
Agents need Context
LLM inference is inherently stateless. The model lacks a memory of previous calls or an awareness of the broader session history. The harness bridges this gap by maintaining the conversation history and working memory to decide what to pass to the model at each step.
Within this architecture, memory and context serve different roles. Memory is what you have based on history, while context is what you can give the model at the present moment. Managing context volume is a delicate balance. Finding that balance by including precise context at the right time is the most nuanced part of building a harness. Excessive data hits the context window limit and degrades response quality, whereas insufficient data causes the model to miss critical information.
As a session grows, the harness must perform "context compaction" to keep the session viable and cost-effective. This process involves summarizing key facts and discarding noise from earlier steps. The goal is to compress the history without losing the thread of what the agent is actually trying to accomplish.
Durable Execution
Beyond providing context, the harness facilitates the agent's ability to reason and act across many steps. It manages tool availability and user permissions while determining how to handle unexpected tool failures or invalid outputs.
For agents operating over hours or days, this execution must also be durable to survive crashes, restarts, or handoffs. The harness handles checkpointing and restoration; coding agents typically lean on the filesystem and Git for this, while other systems use databases and key-value stores.
When something goes wrong mid-task, the harness provides a rollback path to undo changes and reset to a prior checkpoint. Some agents run inside sandboxes or Git worktrees specifically to make these resets efficient.
Recovery becomes significantly more complex once an agent touches external systems. In environments involving databases or third-party APIs, a clean undo often does not exist, and the harness must manage these state conflicts.
Production Engineering
Deploying agents at scale introduces infrastructure challenges similar to those of any high-volume application. In production, the model times out, users do unexpected things. The harness absorbs all of that. To prevent provider lock-in, the harness normalizes interactions across various model APIs. It instruments every reasoning step and tool call to ensure debugging is based on verifiable traces rather than guesswork. This level of observability allows for tracking latency and failure rates to identify issues before they impact the user.
Model providers are compute constrained and often enforce rate limits. Harness manages this, either pass it onto user gracefully or have fallback mechanisms. It applies guardrails, which can range from simple input/output validation to running a separate model to review the agent's actions before they execute. It controls who can run what, with what permissions.
Harnesses also implement feedback loop where structured evaluations are fed back into the system so that the agent can learn and improve over time. This is a critical part of maintaining reliability as agents interact with real users and real data.
Coordination Beyond One Agent
Once the core is solid, composability becomes the next frontier. Custom prompts, tools, skills, and plugins let different users configure agents for their specific needs without touching the harness code.
A well-designed harness also supports multi-agent architectures, such as parallel agents and sub-agents. Managing this coordination, including task delegation and result aggregation, represents its own unique engineering challenge.
Developers can integrate into the agent runtime using hooks to intercept the loop at precise points like before/after tool calls or start and end of session. This allows for adding custom logic without modifying the core harness architecture.
At the far end of the spectrum are long-running autonomous agents: you specify a goal, and the agent explores, iterates, and evaluates until a solution is reached. Since these agents often need broad tool access, the harness mitigates the risk through sandboxed environments and careful scope control. Codex's /goal mode is an early example of this pattern becoming a product primitive.
Agent = Model + Harness
Or harness = agent - model :-)
That's the short version.
If the model provides the core intelligence, the harness is the operating system that makes it useful. It provides the memory, state, and safety infrastructure required for a model to function as a reliable agent. While most focus is on model benchmarks, the harness is frequently the more important variable in production. Two teams using the same model will get vastly different outcomes based on the quality of their engineering.
The major labs are already validating this shift. Anthropic and OpenAI are no longer just selling access to model.
As it’s evident with Claude Code and Codex, the harness itself has become the actual product!
Where Development is Heading
A few directions in this space are worth watching:
Coding agents are acting as universal harnesses. The ability of coding agents to write and update tools themselves makes them extremely flexible when handling unseen scenarios. Couple that with sandboxed code execution and you get powerful primitives for automating work at runtime. Claude CoWork and Codex App are examples of this trend. Both are wrappers over their respective coding harnesses.
Models tuned for harness behavior. This is why Claude Code and GitHub Copilot perform differently on the same underlying tasks - they are not just running the same model with different prompts. The models are trained differently for how they interact with harness primitives: tool use, context compression, and multi-step planning. We will see more of this as companies tighten their grip on the market.
Continual learning. Projects like Hermes are experimenting with agents that update their behavior based on outcomes.
Recursive models. This is still early, but work like Recursive Language Models points toward harnesses that can programmatically slice context and recurse over smaller, more specific sub-tasks.
Harness orchestration as a service. Running stateful long-running agents in production is hard. Providers are now offering harness-as-a-service, with Claude Managed Agents as a clear example.
Where Halios Fits In
Harness is a relatively new infrastructure category. Harnesses evolve over time - you add new tools, adjust prompts, and improve context management as you learn from production runs. This process is harness engineering. I will write about it more in a future post.
Halios helps you evaluate your agent systematically. It gives you visibility into each component of the harness and lets you measure and compare performance so you can make informed decisions about adjustments. Without structured evaluation, you are flying blind. You make a change and hope it works.
If you're building an agent and you want to know whether your harness holds up under pressure - reach out at sandeep at halios dot ai.
Sandeep is Founder of HaliosAI. Follow him on Linkedin, X, and Substack for occasional takes on AI agents, evaluation, and reliability.
Related: How We Improved an AI Sales Agent by 47% Using Structured Evaluation →
We're building agent evaluation infrastructure at halios.ai